Example
Contents
Example#
Here is an example how RIDE can be used at the single trial level to correct speech artifacts in the EEG data.
Loading Python modules#
import matplotlib.pyplot as plt
import pandas as pd
from mne import Epochs, events_from_annotations, set_eeg_reference
from mne.io import read_raw
from pipeline.preprocessing import add_heog_veog, correct_ica
from ride import RideCfg, correct_trials, ride_call
from ride.datasets import get_stark2025
Downloading example data#
The package comes with a function to download an example dataset of one participant
from the Stark (2025) study.
In this EEG experiment, participants performed an object naming task in which a colored frame
around the object indicated whether participants had to name the shown object (condition
simple_naming: 221) or a previously associated one (condition memory_naming: 222).
The raw data are stored on the Open Science Framework and more details about the study can be found in [link to be added].
log_file, vhdr_file = get_stark2025()
Downloading file '2_memory.txt' from 'https://files.de-1.osf.io/v1/resources/289ej/providers/osfstorage/6797c7014e87d78691df2fd9' to '/home/docs/.cache/eeg-ride'.
Downloading file 'VP0302.vhdr' from 'https://files.de-1.osf.io/v1/resources/289ej/providers/osfstorage/6797c1006bf0c8d37bdf2d49' to '/home/docs/.cache/eeg-ride'.
Downloading file 'VP0302.vmrk' from 'https://files.de-1.osf.io/v1/resources/289ej/providers/osfstorage/6797c103794a3a633aa48b69' to '/home/docs/.cache/eeg-ride'.
Downloading file 'VP0302.eeg' from 'https://files.de-1.osf.io/v1/resources/289ej/providers/osfstorage/6797c19d8099c9814c7c2316' to '/home/docs/.cache/eeg-ride'.
Read reaction time data#
The log file contains all reaction times (RTs) from our example particpant.
Note that the RTs are the latencies of the voice key being triggered by the speech output of the participant.
In our example log file, they are stored in a column called vkRT.
Because the RIDE correction is performed for each experimental individually, we subset the
single memory condition ('bedingung_trigger_erp2' == 221).
You can also choose to write a loop over all conditions.
log_df = pd.read_csv(log_file, sep='\t', encoding='ISO-8859-1')
log_df = log_df[log_df['bedingung_trigger_erp2'] == 221]
Preprocessing#
Because the RIDE correction should be performed on cleaned, preprocessed data, we first perform some basic preprocessing steps:
Loading the EEG data.
Setting the correct channel type for non-EEG channels and loading the montage setup for the EEG cap used in the experiment.
Re-referencing to common average.
Performing ICA to correct for eye movement artifacts. We add virtual VEOG and HEOG channels, perform an independent component analysis using the
fasticaalgorithm, and automatically remove components that are likely to reflect blinks or other eye movements. For that, we use the convience functionsadd_heog_veog()andcorrect_ica()from from thehu-neuro-pipelinepackage (see documentation for more details).Applying a bandpass filter between 0.1 and 40 Hz.
Segmentating to epochs around the relevant stimulus trigger. We here use a time window from -0.2 to 1.5 s, which should include the entire spoken response.
Dropping bad epochs and practice trials.
raw = read_raw(vhdr_file, preload=True)
raw = raw.set_channel_types({'IO1': 'eog',
'A2': 'misc',
'audio': 'misc',
'pulse': 'misc'})
raw.set_montage('easycap-M1')
raw, _ = set_eeg_reference(raw, ref_channels='average')
raw = add_heog_veog(raw)
raw, _ = correct_ica(raw, n_components=15)
raw = raw.filter(0.1, 40.0)
events, event_id = events_from_annotations(raw)
event_id = {'simple_naming': 221}
epochs = Epochs(raw, events, event_id, tmin=-0.2,
tmax=1.5, reject=dict(eeg=200e-6))
epochs = epochs[4:] # Remove first 4 epochs because they are practice trials
epochs.metadata = log_df
epochs.drop_bad()
epochs.load_data()
Extracting parameters from /home/docs/.cache/eeg-ride/VP0302.vhdr...
Setting channel info structure...
Reading 0 ... 1195259 = 0.000 ... 2390.518 secs...
EEG channel type selected for re-referencing
Applying average reference.
Applying a custom ('EEG',) reference.
Adding bipolar channel VEOG (Fp1 - IO1)
Adding bipolar channel HEOG (F9 - F10)
Fitting ICA to data using 62 channels (please be patient, this may take a while)
Selecting by number: 15 components
Fitting ICA took 24.3s.
Applying ICA to Raw instance
Transforming to ICA space (15 components)
Zeroing out 1 ICA component
Projecting back using 62 PCA components
Filtering raw data in 1 contiguous segment
Setting up band-pass filter from 0.1 - 40 Hz
FIR filter parameters
---------------------
Designing a one-pass, zero-phase, non-causal bandpass filter:
- Windowed time-domain design (firwin) method
- Hamming window with 0.0194 passband ripple and 53 dB stopband attenuation
- Lower passband edge: 0.10
- Lower transition bandwidth: 0.10 Hz (-6 dB cutoff frequency: 0.05 Hz)
- Upper passband edge: 40.00 Hz
- Upper transition bandwidth: 10.00 Hz (-6 dB cutoff frequency: 45.00 Hz)
- Filter length: 16501 samples (33.002 s)
Used Annotations descriptions: [np.str_('DC Correction/'), np.str_('New Segment/'), np.str_('Stimulus/S 1'), np.str_('Stimulus/S 2'), np.str_('Stimulus/S 3'), np.str_('Stimulus/S 4'), np.str_('Stimulus/S 5'), np.str_('Stimulus/S 6'), np.str_('Stimulus/S 7'), np.str_('Stimulus/S 8'), np.str_('Stimulus/S 9'), np.str_('Stimulus/S 10'), np.str_('Stimulus/S 11'), np.str_('Stimulus/S 12'), np.str_('Stimulus/S 13'), np.str_('Stimulus/S 14'), np.str_('Stimulus/S 15'), np.str_('Stimulus/S 16'), np.str_('Stimulus/S 25'), np.str_('Stimulus/S 51'), np.str_('Stimulus/S 52'), np.str_('Stimulus/S101'), np.str_('Stimulus/S102'), np.str_('Stimulus/S103'), np.str_('Stimulus/S104'), np.str_('Stimulus/S105'), np.str_('Stimulus/S106'), np.str_('Stimulus/S107'), np.str_('Stimulus/S108'), np.str_('Stimulus/S109'), np.str_('Stimulus/S110'), np.str_('Stimulus/S111'), np.str_('Stimulus/S112'), np.str_('Stimulus/S113'), np.str_('Stimulus/S114'), np.str_('Stimulus/S115'), np.str_('Stimulus/S116'), np.str_('Stimulus/S140'), np.str_('Stimulus/S141'), np.str_('Stimulus/S142'), np.str_('Stimulus/S143'), np.str_('Stimulus/S160'), np.str_('Stimulus/S181'), np.str_('Stimulus/S182'), np.str_('Stimulus/S221'), np.str_('Stimulus/S222'), np.str_('Stimulus/S250'), np.str_('Stimulus/S251'), np.str_('Stimulus/S252'), np.str_('Stimulus/S253'), np.str_('Stimulus/S254'), np.str_('Stimulus/S255')]
Not setting metadata
196 matching events found
Setting baseline interval to [-0.2, 0.0] s
Applying baseline correction (mode: mean)
0 projection items activated
Adding metadata with 27 columns
Using data from preloaded Raw for 192 events and 851 original time points ...
Rejecting epoch based on EEG : ['FT7']
Rejecting epoch based on EEG : ['AF7']
2 bad epochs dropped
Using data from preloaded Raw for 190 events and 851 original time points ...
/tmp/ipykernel_2586/791323114.py:1: RuntimeWarning: Channels contain different highpass filters. Lowest (weakest) filter setting (0.00 Hz) will be stored.
raw = read_raw(vhdr_file, preload=True)
/tmp/ipykernel_2586/791323114.py:2: RuntimeWarning: The unit for channel(s) A2, audio, pulse has changed from V to NA.
raw = raw.set_channel_types({'IO1': 'eog',
[Parallel(n_jobs=1)]: Done 17 tasks | elapsed: 0.6s
| General | ||
|---|---|---|
| MNE object type | Epochs | |
| Measurement date | 2023-05-05 at 16:08:02 UTC | |
| Participant | Unknown | |
| Experimenter | Unknown | |
| Acquisition | ||
| Total number of events | 190 | |
| Events counts | simple_naming: 190 | |
| Time range | -0.200 – 1.500 s | |
| Baseline | -0.200 – 0.000 s | |
| Sampling frequency | 500.00 Hz | |
| Time points | 851 | |
| Metadata | 190 rows × 27 columns | |
| Channels | ||
| EEG | ||
| EOG | ||
| misc | ||
| Head & sensor digitization | 65 points | |
| Filters | ||
| Highpass | 0.10 Hz | |
| Lowpass | 40.00 Hz | |
Feel free to adapt the preprocessing to your needs. However, please note that the epochs must be long enough to contain the entire (spoken) response for the RIDE correction to work properly.
Configuring RIDE#
Next, we extract the reponse times vkRT from the epochs metadata. These contain
only the RTs from the good epochs on which we want to base our RIDE correction.
Then, we define the parameters for RIDE:
The names of the RIDE components that should be extracted: The stimulus- (
's') and response-related ('r') components.The time windows (in milliseconds) in which the RIDE are searched for. The time window for the
's'component is relative to stimulus onset (comp_twd:[0,600],comp_latency:0), while for the'r'component, it is relative to the reaction time of the trial (comp_twd:[-400,400],comp_latency:rt). Note that for the'r'component, the time window should be long enough to cover any response-related artifact (the speech artifact) entirely.The sampling frequency of the EEG data, extracted from the epochs object.
rt = list(epochs.metadata['vkRT'])
cfg = RideCfg(comp_name=['s', 'r'],
comp_twd=[[0, 600], [-400, 400]],
comp_latency=[0, rt],
sfreq=epochs.info['sfreq'])
For additional (optional) input arguments, check the function reference for ride.RideCfg.
Running RIDE#
Finally, we can run RIDE on the epoched and cleaned EEG data using our configurations.
The function ride_call() returns the RIDE results.
results = ride_call(epochs, cfg)
WARNING: Extending integer latency 0 to a vector of 0s (one per trial)
Processing electrode #1
Took 10 iterations
Processing electrode #2
Took 10 iterations
Processing electrode #3
Took 8 iterations
Processing electrode #4
Took 10 iterations
Processing electrode #5
Took 9 iterations
Processing electrode #6
Took 9 iterations
Processing electrode #7
Took 10 iterations
Processing electrode #8
Took 9 iterations
Processing electrode #9
Took 8 iterations
Processing electrode #10
Took 9 iterations
Processing electrode #11
Took 10 iterations
Processing electrode #12
Took 8 iterations
Processing electrode #13
Took 9 iterations
Processing electrode #14
Took 8 iterations
Processing electrode #15
Took 9 iterations
Processing electrode #16
Took 9 iterations
Processing electrode #17
Took 8 iterations
Processing electrode #18
Took 10 iterations
Processing electrode #19
Took 9 iterations
Processing electrode #20
Took 10 iterations
Processing electrode #21
Took 9 iterations
Processing electrode #22
Took 9 iterations
Processing electrode #23
Took 9 iterations
Processing electrode #24
Took 9 iterations
Processing electrode #25
Took 10 iterations
Processing electrode #26
Took 9 iterations
Processing electrode #27
Took 9 iterations
Processing electrode #28
Took 10 iterations
Processing electrode #29
Took 8 iterations
Processing electrode #30
Took 8 iterations
Processing electrode #31
Took 9 iterations
Processing electrode #32
Took 9 iterations
Processing electrode #33
Took 9 iterations
Processing electrode #34
Took 8 iterations
Processing electrode #35
Took 8 iterations
Processing electrode #36
Took 10 iterations
Processing electrode #37
Took 9 iterations
Processing electrode #38
Took 10 iterations
Processing electrode #39
Took 8 iterations
Processing electrode #40
Took 9 iterations
Processing electrode #41
Took 9 iterations
Processing electrode #42
Took 9 iterations
Processing electrode #43
Took 9 iterations
Processing electrode #44
Took 10 iterations
Processing electrode #45
Took 7 iterations
Processing electrode #46
Took 8 iterations
Processing electrode #47
Took 9 iterations
Processing electrode #48
Took 10 iterations
Processing electrode #49
Took 10 iterations
Processing electrode #50
Took 9 iterations
Processing electrode #51
Took 8 iterations
Processing electrode #52
Took 9 iterations
Processing electrode #53
Took 9 iterations
Processing electrode #54
Took 8 iterations
Processing electrode #55
Took 10 iterations
Processing electrode #56
Took 10 iterations
Processing electrode #57
Took 9 iterations
Processing electrode #58
Took 8 iterations
Processing electrode #59
Took 9 iterations
Processing electrode #60
Took 9 iterations
Processing electrode #61
Took 9 iterations
Processing electrode #62
Took 9 iterations
Inspecting the RIDE results#
The output of the ride_call function is an object containing, among other things, the RIDE components.
It also comes with a plot() method to visualize the components.
The plot shows the average ERP for all electrodes and the ERP split into the 's'-component (stimulus-
related) and the 'r'-component (response-related), i.e. the speech artifact at the median (?) latency.
Check the RideResults reference for further output details.
_ = results.plot()

Correcting the original data#
The package comes with a separate function to correct the EEG data based on the RIDE results at the
single trial level. To “clean” the EEG from the speech artifact, the function correct_trials()
subtracts the 'r' component from the single trial data, shifted by the single trial RTs.
epochs_corr = correct_trials(results, epochs)
/home/docs/checkouts/readthedocs.org/user_builds/eeg-ride/conda/latest/lib/python3.11/site-packages/ride/correct.py:40: UserWarning: Trials [] will NOT be RIDE corrected because their latency is NaN or zero.
warn(f'Trials {nan_ixs} will NOT be RIDE corrected because their latency is NaN or zero.')
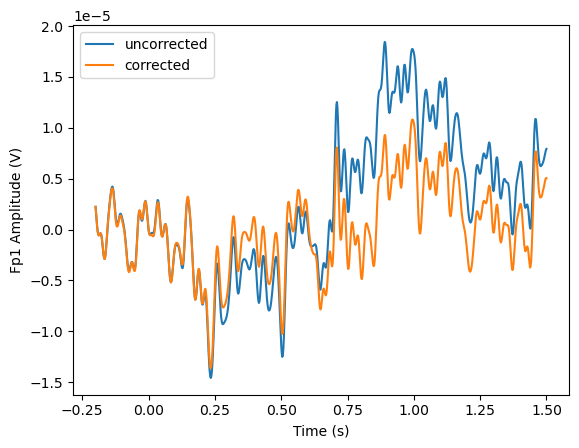
Now we can compare the raw and corrected data for one example epoch:
data = epochs.pick('Fp1')[0].get_data().squeeze()
data_corr = epochs_corr.pick('Fp1')[0].get_data().squeeze()
times = epochs.times
_ = plt.plot(times, data)
_ = plt.plot(times, data_corr)
_ = plt.legend(['uncorrected', 'corrected'])
_ = plt.xlabel('Time (s)')
_ = plt.ylabel('Fp1 Amplitude (V)')
Using RIDE in our pipeline#
Instead of manually coding your preprocessing and RIDE correction, you can also use our hu-neuro-pipeline package based on the Frömer et al. (2018) pipeline.
If you add the perform_ride=True argument, this will perform the preprocessing and
the RIDE correction in one go.
Check the documentation of this package for managing the RIDE-related input options.